Robert D. Holmstedt
Ancient Hebrew Syntax Database

The Holmstedt-Abegg Syntactic Database of Ancient Hebrew
In 2008 Robert Holmstedt (University of Toronto) and Martin Abegg (Trinity Western University) began collaborating on the development of a syntactic database for all ancient Hebrew texts. This project was spurred by the release of two syntax databases that cover the Hebrew Bible, the WIVU Emdros database of the Werkgroep Informatica of the Vrije Universiteit in Amsterdam and the Andersen-Forbes Analyzed Text of the Hebrew Bible. While both existing databases were produced by noted Hebraists and are thus immensely valuable, we saw a need for a third database: one that was focused narrowly on syntax (see distinctive #3 below) and covered both biblical and extra-biblical texts (see distinctive #1). After contacting various current Bible software companies, in November 2008 the decision was made to work with OakTree Software and their Accordance Bible program.
(We gratefully acknowledge that this project has been partially funded with a grant (#410-2010-796) from the Social Sciences and Humanities Research Council of Canada.)
Although both existing databases (as well as a third database in production; the Westminster Hebrew Syntax database) are ground-breaking in distinct ways, 4 features make our project unique.
1) The Holmstedt-Abegg database covers all ancient Hebrew in the first millennium B.C.E. This will not only provide access to the non-biblical texts, it will also facilitate comparative and historical syntactic analyses (e.g., comparing the syntactic features of ‘late’ biblical books to select Qumran texts).
2) Our project has not been designed as a stand-alone database, but is native to the Accordance Bible database software. Although the data files are simple enough so that they could be easily incorporated into any existing database software, the advantages of working with an existing software package have been manifestly clear: access to programming expertise at every step of development and the luxury of not needing to use any existing mark-up language, such as html or xml, or database engine, such as Emdros. Additionally, the search interface in Accordance provides an intuitive approach to searching the data, combining morphological and syntactic elements in the same argument.
3) The H-A database is focused very tightly on clause syntax: we build on existing morphological databases (which also facilitates our schedule) and do not address semantic or discourse-pragmatic features of the Hebrew texts. In contrast, the Andersen-Forbes database, for example, includes such non-syntactic issues as semantic categories (e.g., as ‘purpose’, ‘result’, even ‘undesired outcome’) and additional issues of less grammatical import such as the time, region, dialect, register, and/or source of the biblical texts (Andersen and Forbes 2003:44).
4) The H-A database is carefully grounded in formal (generative) linguistic principles of syntax, e.g., hierarchical phrase structure and the inclusion of covert or ‘null’ constituents. Yet, in order to remain broadly usable, our approach eschews numerous theory-specific concepts (e.g., we do NOT recognize constituent movement, although we do deal with discontinuous constituents, which one may or may not ascribe to constituent movement).
This project represents a unique combination of expertise: Holmstedt’s background in Hebrew philology and formal (generative) syntax and Abegg’s background in Hebrew philology, knowledge of the Qumran and Ben Sira texts, and experience in tagging electronic texts. Moreover, the primary Accordance programmer's - Roy Brown - computer expertise and competence in Hebrew has been an additional critical advantage.
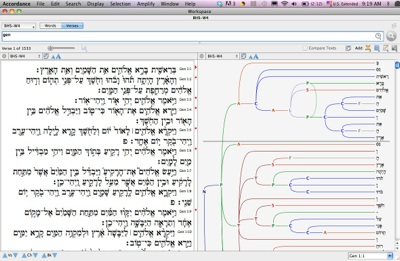
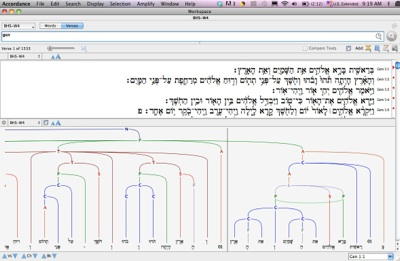
In September 2010, the first stage of the project was released publicly. The syntax searching functions within the Accordance Bible software appeared with the release of Accordance 9.0 and the syntactic data for the book of Genesis was made available through Accordance.
Update: In November 2010, the second set of Hebrew books were added to the module: Joshua, Joel, Amos, Obadiah, Jonah, Nahum, Habakkuk, Psalms, and Ruth.
In addition to the new syntax searching functions within Accordance, the syntactic data has also been represented visually by means of ‘trees’ that can be displayed alongside the Hebrew text.
Syntactic data for a number of biblical texts will be continue to be released as their are finished. The project goals include the completion of the Hebrew Bible, all Hebrew epigraphic texts, all Qumran texts, and the Hebrew texts of Ben Sira by late 2012 or early 2013.
Papers relating to the Project
1.R. D. Holmstedt. “Understanding and Using the New Syntax Searching Capabilities in Accordance 9.” Paper presented at the Accordance Users' Conference, Dallas, September 25. (download PDF)
-- A very general description of the history, linguistic principles, and tagging methodology behind the syntax project. For a general Accordance user audience. Includes a few simple syntax searches on the earliest release (Genesis and Accordance 9.0.3).
2. Ancient Hebrew Syntax: Making a Searchable Database. Blog post (with downloadable PDF version).
-- A more detailed description of the linguistic principles and tagging methodology behind the syntax project.