LIN 199.22W: Exploring Heritage Languages
HW 4: Exploring attitudes to heritage languages
Learning Objectives
- You will learn about the corpus-informed discourse analysis method.
- You will learn to use ELAN to explore transcribed speech: search (ELAN has great tools for this) with regular expressions, and ECV (external controlled vocabularies).
- You will learn to use Excel to organize data in pivot tables and charts; OR you will learn to create and interpret word clouds.
- You will make connections with Attitude theory by exploring several dimensions of language attitudes.
Materials needed
- ELAN and Excel software
- HLVC IV transcriptions, available through Corpora in the Classroom
- HLVC recordings (.wav or .mp3), available (zipped) also through Corpora in the Classroom
- premade "Controlled Vocab for Attitudes" ECV (External Controlled Vocabularies), available in Quercus with this assignment
- Regular expressions (RegEx) overview
- Optionally, consider these Word cloud websites
Outline a research report with these sections:
- Introduction
- Background
- Methodology
- Results
- Discussion
- Conclusion
Provide as much detail as you know, but don't worry about beautiful prose yet.
Overview of your task
(Below this overview, you will find step-by-step instructions)
As a first step for the assignment you will learn about and explore the HLVC corpus. You should listen to some interviews and review the Ethnic Orientation Questionnaire (from HW 3). In class, students will get an overview and learn more about how collecting data for the HLVC project is administered. Students speaking Russian, or one of the other heritage languages in the HLVC Project, can work together with other students who do not speak the language – summarize and maybe partly translate what is being heard/read.
If there is a group with NO members that can work with one of the HLVC languages, you can instead use the English-language interviews from the Contact in the City corpus (also available through the Corpus in the Classroom server). Methods are the same.
This exploration should result in a discussion about first impressions and what the students think are dominant and recurring themes when heritage speakers talk about their cultural and linguistic heritage. You will formulate hypotheses about the participants’ attitudes towards their heritage language.
To test the hypotheses, start your research using the ELAN files which provide segmented transcriptions of the interviews. With the help of ELAN’s search tools and your acquired knowledge about regular expressions, decide on search terms and start searching. In the .eaf files, create tiers and use the controlled vocabularies to code the comments you find. These controlled vocabularies include 3 "Evaluation" levels for connotation: positive, neutral, negative and 9 Lg Comment Topics that you can use to categorize the relevant comments you find. After finalizing these annotations in ELAN, export them to Excel so you can create pivot tables to create well-arranged visualizations/tables of your results.
|
Figure 1: Screenshot in ELAN showing the annotation of a search result for 'Russian language'. The highlighted sentence says, 'And the Russian language is my life, I love it'. It is connotated as positive and classified in the semantic category ‘appreciation/admiration of Russian’ (we are now calling "semantic category" "topic"). |
Lg Comment Topics
|
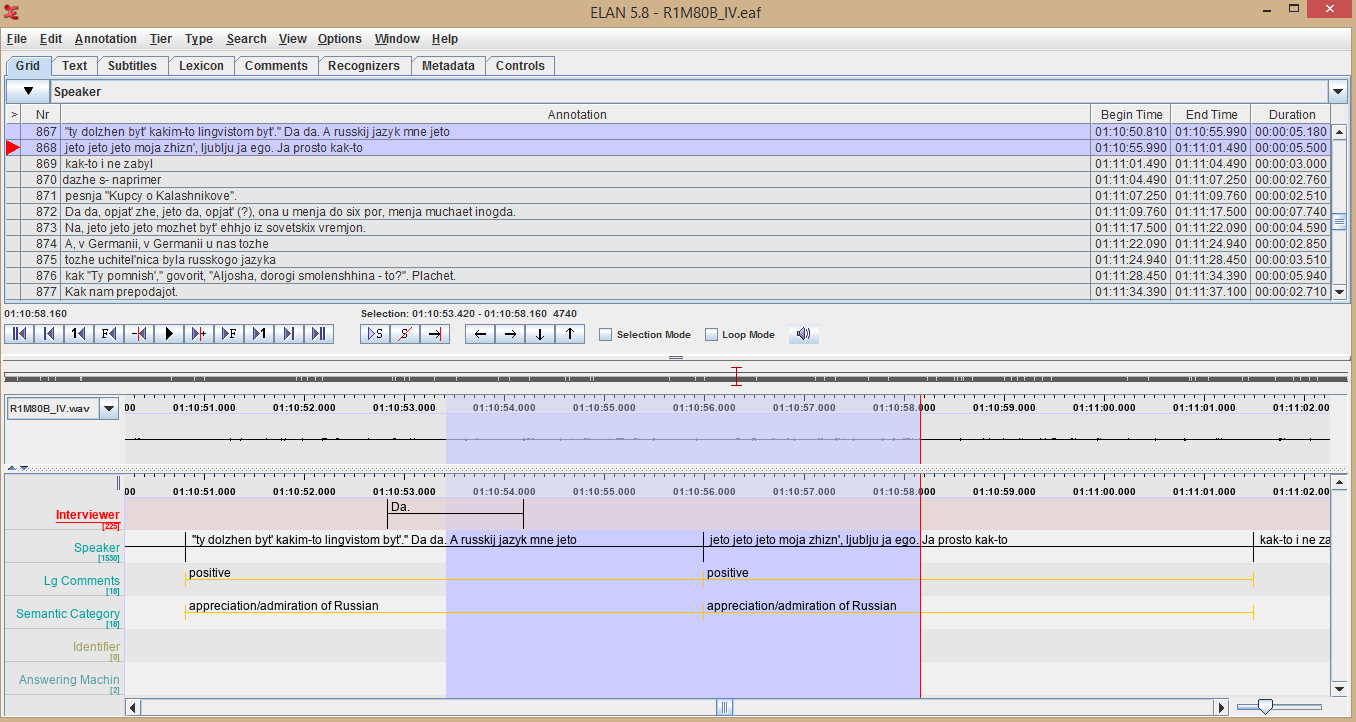
In order to create a pivot chart, click on PivotChart in the Insert tab in upper menu (Or "Summarize Data with Pivot Table" in the Data menu).
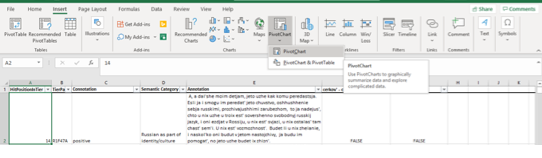
Figure 2: Screenshot in Excel showing how to create a pivot chart
Accept the suggested settings and create the pivot chart in a new sheet. Start filling your pivot table by choosing fields and experimenting with how the pivot table looks by dragging fields to the different areas – filters, legend, axis, and values.
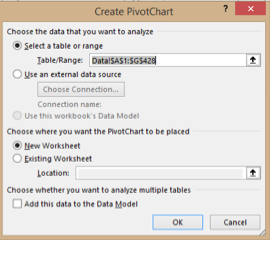
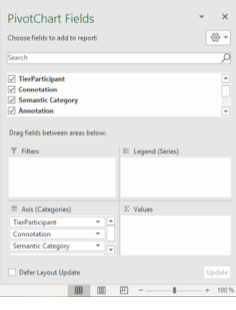
Figure 3: Screenshots in Excel showing the preferred settings for creating a pivot chart and the settings for editing the structure.
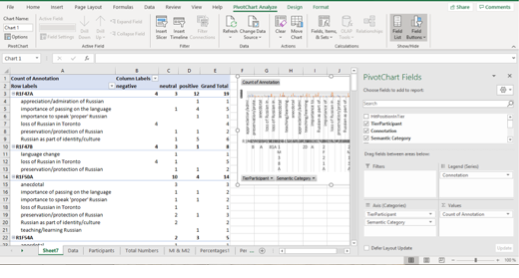
Figure 4: Screenshot in Excel showing one form how a pivot table and chart can look like with selected settings shown on the right.
Results could then be visualized like this:
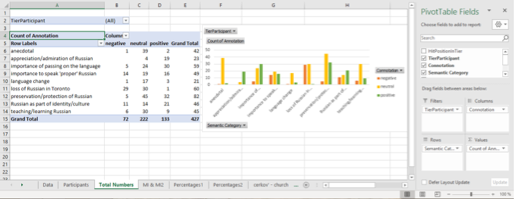
Figure 5: Screenshot in Excel showing a pivot table summarizing and visualizing the dataset.
As an alternative to pivot tables, you can work with word clouds to visualize frequencies of words. For that, the transcriptions have to be exported from the ELAN files, either from separate files or from multiple files at the same time. Text files then can be uploaded onto websites like wordclouds.com, https://www.jasondavies.com/wordcloud/, or worditout.com. When working with wordclouds.com students can access a word list and edit it by, for example, deleting function words and giving content words more weight in the word cloud. This could look like this:

Figure 6: Example word cloud. Retrieved from wordcloud.com.
Then, interpret these results. How do (Russian) heritage speakers refer to their language, how can their attitudes be described? Can you detect differences and are there reasons for them? All this should be noted in your research report outline (and later, expanded in your final assignment).
Step-by-step instructions
1. Brainstorm some possible hypotheses about the types of comments that different speakers or groups of speakers might make that reflect their language attitudes.
2. Select six files from the HLVC or Contact in the City Corpus, using the Corpora on the Classroom website. Download matched sets of SPEAKERCODE_IV.eaf and SPEAKERCODE_IV.wav files in your selected language/ethnicity.
- Select at least 6 speakers from the HLVC project.
- These files are stored in the Corpora in the Classroom website.
- Choose speakers for whom there is both a SPEAKERCODE_IV.zip and a SPEAKERCODE_IV.eaf file. (You might also listen to the SPEAKERCODE_EOQ.zip, but these are not transcribed, so you would need to set up an .eaf file and transcribe the relevant comments.)
- For each, download the .zip and the .eaf.
- Unzip the .zip file to get the .wav (audio) file.
- Save these files in the same folder (the ELAN .eaf file needs to find the .wav).
- Download ELAN, a time-aligned transcription program and its manual (or bookmark the online manual). ELAN is freeware and works on Mac, Windows and Unix platforms.
- Once you have ELAN on your computer, use it to open the SPEAKERCODE_IV.eaf file that you selected.
- Save the file.
- Choose the Automatic Backup > 1 minute option in the File menu.
- Click around and listen to bits.
- Explore the different buttons and menus in ELAN for a few minutes. You may find parts of this file helpful: ELAN_annotation_tips.pdf, as well as the manual for ELAN.
- Download this file from HW4 in Quercus: Controlled Vocab for Attitudes.ecv . Or it might be a shortcut to import the tiers from this file, also in HW4: tiers & CV for attitude.eaf.
3. In each file to be analyzed, create 2 new Types (look in the Types menu). Name them:
LgComments Topics
LgComments Evaluation
4. For each, assign the Stereotype “Symbolic Association”.
5. In each Type, add the “External CV” by clicking the "External CV" button, then going to Edit menu and choosing “Edit Controlled Vocabularies.” Pick the matching CV when prompted. (This is the .ecv file you downloaded from Quercus.)
Click the Add button at the bottom of the New Types window to save each change.
6. Then, you need to create 2 new Tiers (look in the Tiers menu), also named:
LgComments Topics
LgComments Evaluation
7. Fill in New Tier attributes like this, assigning the matching Tier Type that you created previously:
Add your own initials as the "Annotator" and be sure to fill in the SPEAKERCODE in the "Participant" field.

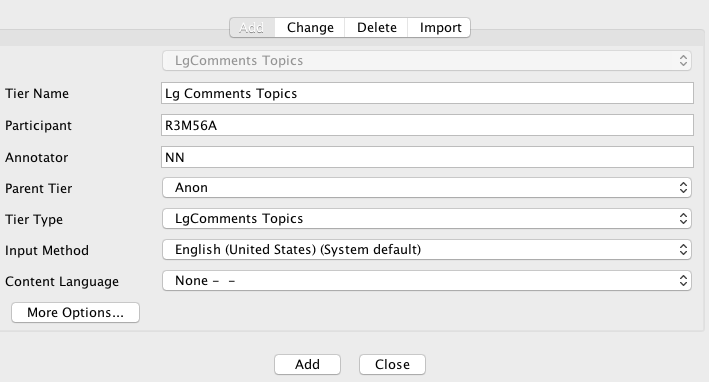
8. And click “Add” button at the bottom of the Add Tier window. (Repeat to add a second tier.)
9. Save your file.
10. Now, when you click to select an utterance in the Speaker tier (a tier which might be named with a Speaker code or as “Anon” for Anonymous or as "Speaker"), and then double-click in the LgComments Topics or LgComments Evaluation tier, you will get a pull-down menu letting you choose entries to code the data.
11. Think about how to SEARCH the interview file (or listen/read through) for comments about the heritage language. What terms might speakers use to refer to their heritage language? Use “regular expressions” to find many comments at once. Explore the options to search multiple files at once (a "domain" is a folder where you have all the .eaf files that you want to search at once)
12. Each time you find a comment related to attitudes toward the heritage language, code it on the Topics and Evaluation tiers you created.
13. When you have gone through the entire file and coded all relevant comments, export the tiers with the transcription and your codes for Topics and Evaluation as a “tab-delimited text file.” You will find “Export As” options in the File menu. Choose exactly these options:
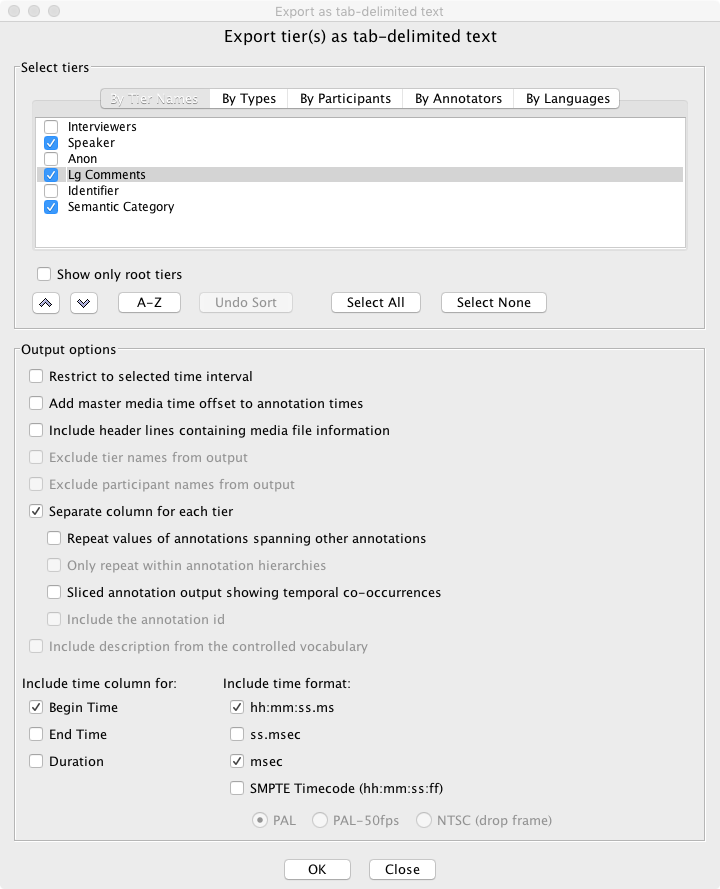
You might also explore the Export from Multiple Files option.
14. Open this exported file in Excel so that you can explore it with Pivot Tables.
15. In order to see just the relevant comments, select all cells, then sort by the “Lg Comments Topics.” You can then easily delete all the lower rows that don’t have anything in that column – you won’t need them.
16. You will then have a spreadsheet like this:
|
Begin Time - hh:mm:ss.ms |
Begin Time - msec |
Speaker |
Lg Comments Evaluation |
Lg Comments Topics |
|
03:11.9 |
191870 |
i nam peredali vot russkij jazyk. I i oni schitajut, chto jeto vazhnee, chem |
neutral |
importance to speak 'proper' Russian |
|
45:11.7 |
2711680 |
soxranenie russkogo jazyka. Tak chto, tak chto glavnym obrazom deti v jetoj, jetoj russkoj shkole rodilis' |
neutral |
preservation of Russian |
|
45:17.6 |
2717600 |
libo v Rossii, libo za granicej, i u nix russkie roditeli, tak chto oni vospityvajutsja chtisto po-russki. |
neutral |
passing on the language |
|
45:28.8 |
2728830 |
mezhdu nimi razgovornye rech' jeto vsjo na russkom jazyke, a teper' jeto pereshlo na anglijskij uzhe, da. |
neutral |
loss of Russian in Toronto |
|
47:44.4 |
2864360 |
xotja on, on on po-russki malo govorit, no vsjo-taki ne skryvaet to chto on russkogo prois-, russkogo proisxozhdenija. |
neutral |
Russian as part of one's identity/culture |
|
32:55.5 |
1975500 |
vidim chto jeto my xodim po-russki, a teper' luchshe po-anglijski, togda nikto ne pojmjot. |
positive |
language change |
|
38:53.3 |
2333250 |
I esli chelovek ne uveren, kaka-ja to starushka k ljubomu na russkom jazyke, da, da. Jeto zdorovo. |
positive |
preservation of Russian |
17. After deleting unneeded rows, again Select All and re-sort by the “msec” timestamp to get comments back in their original chronological order.
18. Change the name of the “Speaker” column to “Comment.” If you have data for each speaker in separate files, add a column for the SPEAKERCODE and then copy the data for all your speakers to one Excel file.
19. Play around with the PivotTable function (in the Data menu in my version of Excel). You might create something like this:
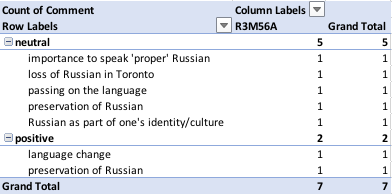
or it might be fancier, with comments sorted by speaker, gender, generation, or language...
20. Now, think about what sort of hypothesis you can generate, or revisit your hypotheses from before.
21. As an alternative to working with Pivot Tables in Excel, you can explore creating Word clouds from the list of comments instead. I do not provide specific instructions as you can find several online options for this. It will be a more qualitative exploration of the data – you won’t get countable results.
22. When you feel like you have created a PivotTable or PivotChart (or Word clouds) that gives you a good understanding of your data, save these files to submit them with your assignment.
23. As a group, you are ready to outline your paper, noting how the data support or contradict your hypothesis. (You will write the paper more fully for the final assignment of the course. That will be a solo writing assignment.)