Autoencoders & Variational Autoencoders
Written by Xi Huang
What is an autoencoder?
The traditional autoencoder is a neural network that is based on
the idea of finding representation of latent information, also known
as the encoder-decoder architecture. As the name suggests, it consists
of two main components: the encoder and the decoder.
The point of the encoder is to take in a data point and convert it into
a low-dimensional embedding of the original input, or in other words, a
latent representation. For example, if we are working with images of
handwritten digits from the MNIST dataset with an autoencoder,
the output of the learned encoder can be some condensed representation of the digit that the
input image is supposed to portray, such as a unique combination of the
digit’s features among the set of its handwritten depictions.
On the other hand, the decoder is designed to take in the low-dimensional
embedding and “reconstruct” the input data. The reconstruction may not be the same
as the input since the decoder starts off with the embedding, but the goal for training
is to output something close to the input, minimizing the loss of information
in the embedding process measured by a loss function. For the MNIST example,
the autoencoder can take a handwritten digit input, extract the digit’s features
into an embedding with the encoder, and generate its original “handwritten”
look of the same digit with the decoder. This process is unsupervised, since
we do not need labeled data, and compare the output with the input directly
instead.
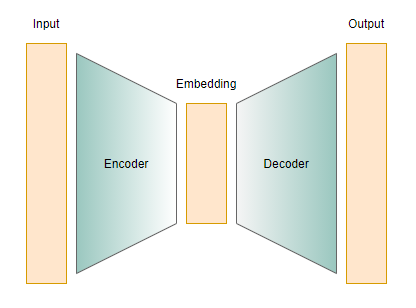
Figure 1: Architecture of a traditional autoencoder
Now, what is a variational autoencoder (VAE)?
Variational autoencoder is an adaptation from traditional autoencoder. Instead of embedding the input into a vector representation, the variational autoencoder architecture embeds the input into a distribution. Then, the decoder samples from that embedded distribution and construct a generated output. For example, going back to our MNIST example, now we have a model that can embed the distribution of latent characteristics of a digit, and then recreate a “handwritten” portrayal of the digit based on features sampled from its learned distribution embedding. In addition, during training, KL-divergence is usually used as a regularizer as its purpose is to compare the similarity between two distributions.

Figure 2: Architecture of a VAE with a Gaussian distribution embedding
One main advantage that VAE has over traditional autoencoder is that sampling from the embedded distribution allows the model to generate new data that comes from the same embedding distribution as the input data. Meanwhile, traditional autoencoder can only generate one output similar to its input since its structure is deterministic.

Figure 3: VAE is more powerful than "vanilla" autoencoder
In my current project, we are exploring the use of VAE to generate music data. We work with a dataset called the Lakh MIDI Dataset. Since sequential information is essential when it comes to music, we are experimenting with a bidirectional encoder utilizing LSTM to capture temporal relationship in the data. Similarly, a LSTM is used for the decoder to recreate a music sequence. Here is a blog post related to this topic from a previous work called "MusicVAE".
References
[1] C. Doersch, Tutorial on Variational Autoencoders (2021), arXiv
[2] P. Janetzky, Generative Networks: From AE to VAE to GAN to CycleGAN (2021), Towards Data Science
[3] A. Roberts, J. Engel, C. Raffel, I. Simon, C. Hawthorne,
MusicVAE: Creating a palette for musical scores with machine learning. (2018), Magenta