- Choose Open from the File menu and select one of the .eaf files that you downloaded. "eaf" indicates an ELAN Annotation File.
- You may be asked to locate the .wav file that has the same name as the .eaf file, or ELAN may find it automatically.
- Choose AUTO BACKUP > 1 minute from the File menu. Although this should make ELAN save your file every minute, please select "Save" from the "Edit" menu regularly as you work. Back up onto a different disk at the end of every work session, at least. Losing the work you have done when/if your computer crashes is NOT a valid reason for an extension, unfortunately.
- In the Edit menu, select Preferences > Edit Preferences > Editing. Make sure the box labeled "Enter key commits change in the inline box" is checked.
- Immediately save your file as YOURLASTNAME_YOURFIRSTNAME_SPEAKERCODE.eaf. For example, I might create "NAGY_NAOMI_F70W.eaf." (The program will add the ".eaf" suffix to indicate that this is an ELAN Annotation File.)
- In the Tiers menu, choose Change Tier Attributes. Put in your name in the Annotator field for the following tiers:
- tokens
- dependent variable
- preceding vowel
- following context
- Put on headphones that are plugged into your computer.
- You should see a soundwave in the center of the ELAN window. (Have a look at this picture) If you don’t see the wave, Command-Click or Right-click on the place where the soundwave should be (it will be showing as a flat horizontal line). This creates a pop-up menu. Choose a number to magnify/Vertical Zoom by. (See ELAN manual on vertical zoom.) Test and adjust your volume. (Apple menu > System Preferences > Sound > Output for a Mac).
- Click around on some buttons in ELAN and explore what they do. (Hovering over most of them will bring up an indicator of their function.)
- In the Options menu, make sure Annotation mode is selected.
- In the tabs that run across the top of the soundwave window, select Controls to adjust volume and speed of playback. Then switch to the Grid tab. Here you will see a list of everything that has been transcribed in the selected tier, along with the timepoints at which each items started end finished. There's a pull-down menu above the tabs from which you can select different tiers to view in "grid view."
- Your window should look like this.
- In the tier labeled "tokens," create an annotation field that corresponds to the syllable in the .wav file where the first (r) is spoken. To do this, highlight a portion of the .wav. Listen (Shift+S, or click the Play button with the blue triangle) and see if it's the right part. If not, keep looking and listening. When you have highlighted the right section, double-click in the "tokens" tier to create an annotation field in which to code that token. When you double-click, a field will be created that is the size of the portion of the .wav that you highlighted. That field, and whatever text you type in it, is time-linked to that part of the .wav. Afterwards, you can click that field and hear the corresponding syllable.
- In the annotation field, type the word that contains the (r).
- Continue through the file, following the principle of accountability, to label the first 50 words containing an instance of (r). (In a word like "harder", which contains two tokens of (r) you could mark one syllable as "harder1" and the other as "harder2".)
- Circumscribe the variable context. “Circumscribing the variable context” means determining what tokens will be included in your analysis and what will not be included, with principled reasons. Although you should mark all instances of syllables that appear to contain (r) (up to 50), i.e., /r/ in a syllable coda, you might later exclude some tokens when you make your distributional analysis charts (See Part 7 below).
- Be sure to only code coda /r/s, NOT any /r/s that appear in the onset of a syllable.
- Analyze the data from the main speaker only. Ignore anything said by anyone other than the main speaker (the speaker for whom the file is named) for this assignment.
- If there are any tokens you can't decide whether to include or not, make a note about it in the "Default" tier (or create a Notes tier), at the appropriate timepoint.
- In the tier labeled "dependent variable," create an annotation field that corresponds to the syllable in the .wav file where the first (r) is spoken (the field in your "tokens" tier). To do this, click the field in the "tokens" tier to highlight in. Then click in the "Dependent variable" tier just below the highlighted annotation field in the "tokens" tier. (A field will be created that is the same size as the field in the "tokens" tier.)
- In each annotation field in the "Dependent variable" tier, type "r" if you hear the [r] pronounced. Type "0" (zero) if you hear only a vowel, but no consonantal [r]. Hit "enter" after typing in the appropriate code. This will save what you typed and move the cursor out of the annotation field.
- Once you have marked and coded the first few tokens, your file should look something like this.
- To check if you are on the right track, export your file as a tab-delimited text file.
- In the File menu, choose "Export as..."
- Select "Tab-delimited Text"
- Under Select Tiers, click the boxes for "main speaker", "tokens" and "dependent variable."
- Under Output options, select the boxes for "Separate column for each tier" and "Repeat values..."
- Click "OK" and then "Close."
Open the newly created .txt file in Excel. (If you get the Import window, just click "Finish.") Somewhere in your .txt file (you may need to scroll to the bottom), there should be a few rows that look like this:

Note: Capitalization matters when you are coding tokens! "R" will not be seen as the same thing as "r" when you start running your analyses.
[Return to top] [Return to syllabus]
Part 4: Code the independent linguistic variables in ELAN
For this Part, you will be working with the six ELAN .eaf files that you created in Part 3.
Note: Capitalization matters when you are coding tokens! "e" will not be seen as the same thing as "E" when you start running your analyses.
Code each of the tokens for two independent variables. To do this, highlight a token, then click in the relevant tier ("preceding vowel" or "following context"), right below the token. In the new field that appears, type in the 1-letter code that describes appropriate context. Be sure to code what you hear, not what the spelling suggests -- this may vary across speakers. If you need to make any notes about questionable tokens, etc., type them in the "Default" tier so you can find them later.
Categorize what you find in the data using the following coding scheme as a start. If you find a token that does not fit the existing categories, you can make up a new category and use it. Make sure to make a note of what your new abbreviation means and submit that with the assignment.
| Code | IPA Symbol | Description | Example word |
|---|---|---|---|
| i | i or ɪ | high front | "beer" |
| e | e or ɛ | mid front | "bear" |
| a | ɑ, a or æ | low | "bar" (for some speakers, some tokens) |
| o | o or ɔ | mid back | "bore" |
| u | u or ʊ | high back round | "boor" (or "Bloor") |
| 2 | ə | unstressed mid central (schwa) | "runner" |
| 3 | ʌ | stressed mid central (caret) | "purchase" |
| x | j | glides or other sounds | "your" as [jr] or "p'ticipate" |
| Code | Description | Example |
|---|---|---|
| v | Word-final, preceding a vowel | "car is" |
| p | Word-final, preceding a pause | "car." |
| c | Following consonant, in the next morpheme and in the next syllable | "wintertime" |
| d | Following consonant, in the next morpheme but the same syllable | "winters" |
| s | Morpheme-internal (Following consonant, in the same morpheme) | "card" |
You can find more examples for each variant in the reading.
Your file should now look something like this.
[Return to top] [Return to syllabus]
Part 5: Code the independent social variables in ELAN and export to a .txt file
The final step in coding your tokens is to add a single annotation in the "social factor codes" tier. This annotation must be the length of the entire recording. It should contain a 3-letter code that describes the speaker: age group + sex + ethnicity. Refer back to Table 1: The Speaker Sample.
Your ELAN file should now look like this.
Once you have coded all six files, check your coding for accuracy and consistency.
The next step is to export your coded data, along with the transcription and timestamps, to a .txt file for statistical analysis.
To export a file:
- In ELAN, choose Export as > Tab-delimited Text from the File menu. (If you are brave, you can experiment with the Export Multiple Files As function.)
- In the Select tiers box, click main speaker , tokens, and the tiers for all the variables you coded (dependent and independent, linguistic and social).
- In Output options, click "Separate column for each tier" and "Repeat values..."
- In Include time column for, click "Begin Time" and "End Time."
- In Include time format: click on the first box.
- Click OK.
- Name the file SPEAKERCODE_YOURLASTNAME_YOURFIRSTNAME.txt when you save it.
- Follow the same process for all six speakers.
To prepare your data to turn in:
- Open each .txt file (one for each speaker) in Excel.
- Paste them, one below the other into one Excel file. Make sure the same kind of information appears consistently in each column, for all the speakers.
- Save this new Excel file as YOURLASTNAME_YOURFIRSTNAME_LIN351_tokens.xls.
- Select All.
- From the Data menu, choose Sort.... Sort by "social factor codes" and then by "Begin Time."
- After sorting, please delete all the rows that do NOT contain tokens. (They will have nothing in the "Begin Time" or "Dependent variable" columns, so it's easy to select them all and delete in one action.)
- Save As... YOURLASTNAME_YOURFIRSTNAME_LIN351_tokens.txt. (This is a tab-delimited text file format.)
- Submit this .txt file electronically in the Assignments section of Blackboard.
Submit your signed Corpus Data Release Form in tutorial the day this is due, if you did not do so previously.
No credit will be given to any student who has not submitted this form. You will find the form in Blackboard.
[Return to top] [Return to syllabus]
Part 6: Getting Goldvarb started
At this point, we transfer the data from Excel to Goldvarb. We will use Goldvarb to conduct our analysis. It’s a statistical program created just for sociolinguists. It can provide counts (N), percentages (%) and factor weights showing how frequently the different variants of your dependent variable appear in various contexts. Although you could do counts and percentages in a spreadsheet program like Excel, Goldvarb allows you to go one step further to a multivariate analysis. These allow you to see how much effect each independent variable (aspects of the context: linguistic, social, and stylistic) has on the dependent variable (the phenomenon you’re studying).
Download Goldvarb. It is available for Mac, Windows, or Linux. See link in Blackboard or download directly from:
http://individual.utoronto.ca/tagliamonte/goldvarb.htmGoldvarb requires the code for each token to be enclosed between a left parenthesis “(“ and some white space. So, to easily create a token file that is formatted appropriately, add the following formula to the first blank cell to the right of your first coded token in your Excel spreadsheet: ="("&E2&F2&G2&H2&" "&D2&" "&C2. (Between the two double quotes that look adjacent on this webpage, you should type 3 spaces. There are 2 pairs of adjacent double quotes) Be sure to type this formula into your Spreadsheet rather than copying it from the webpage. Apparently there are issues with the quotation marks otherwise.
Your spreadsheet should now look like this:
A B C D E F G H I 1 Begin Time main speaker tokens dependent variable preceding vowel following context social factor codes Token as it appears in Column I Token formula 2 00:00.8 the following words are from... words r 2 c YFW (r2cYFW words the following words are from... ="("&D2&E2&F2&G2&" "&C2&" "&B2 3 00:00.9 the following words are from... are r a v YFW (ravYFW words the following words are from... Note: Cell I2 shows the formula that you should type in. The cells in Column H show what it will produce in this table. (Type it once into Cell I2 and Fill Down for the rest of the column.) If your columns are in a different order, either re-order them or change the formula accordingly.
This will create an appropriately formatted token in the cell where you typed this function.
Copy this formula down the full column so that you have each token formatted this way.
Copy only this column (here, Column H) into a New Token file in Goldvarb. To do this:
Prepare the token file
- Open Goldvarb.
- Select "New" in the "File" menu.
- Add ".tkn" as a suffix to whatever title you choose.
- Select "Tokens" as the type of new file.
- When it asks you to select number of groups, type the number of elements you will have in each token (7). Then hit return or "OK". You can always change the number of elements, so just click "OK" and go on if you aren't sure.
- Enter your tokens, one per line. You will easily do this by pasting in the one column of formatted tokens from your Excel spreadsheet (Refer back to Part 6.).
- Each token line must begin with an open parenthesis "(".
- Separate the token from following material by at least 3 spaces or a tab.
- Anything in a line that doesn't begin with "(" will be ignored by the program, so you can label different parts of your file by writing whatever you want on a line that doesn't begin with "(".
- You can also add any comments, to be ignored by the program but useful to humans, by starting the line with a semicolon “;”. You might wish to add a comment line indicating where your each speaker’s tokens begin, for example. Or you might add a comment so you can easily find your favorite token.
FYI, there is a "search & replace" command in the "Tokens" menu which you can use to automate repetitive tasks. For example, assume every line needs to have a "N" as the second element of the token (representing the speaker "Naomi", and you have used "y" and "n" as the first element of your token. Select "search & replace" and replace each "y" with "yN" and then each "n" with "nN".
FYI, You can cut and paste to and from a token file for editing, just like in Word.
Save the token file. Name it LIN351_Last-Name_First-Name.tkn.
Check your token file.
- In the Token menu, choose "Generate factor specifications." This will make a list of all the characters you used in each column. You can see these in the little window below your token file. Click through the factor groups and make sure there are no anomalous characters (likely indicating typos or missing elements in a token).
- Alternatively, you can enter the factor specifications into the "Factor specification" window and then select "Check tokens" at the program will look for lines that have an anomalous character (i.e., one that you didn't specify for that group.)
- If it asks you to "Set fill character," just type "/" and say ok. That means that if you have any token string that isn't long enough (you specified the length at the beginning with "Select number of groups") it will fill in "/"'s to fill out the line-- then you'll see them and check what you missed.
[Return to top] [Return to syllabus]
Part 7: Distributional analysis using Goldvarb
First, make sure your Token file (from Part 6) is open in Goldvarb.Prepare the Conditions file
This is where you choose how to sort your data. For starters, you do a general sort of all your data, to show the distribution of each dependent variable with respect to each variant of the independent variable.
- In the Token menu, choose No recode. This will give you a general overview of the tokens and patterns you have.
- Save your new Conditions file (with .cnd suffix).
- Name it something that will make sense like "all" or "first" or "Vanessa."
Add the suffix ".cnd" to the name, if it doesn't automatically appear.
Note that the program suggests an appropriate name, but it will always suggest a name that is the same as your token file name, and you will probably make several different condition files from your token file. - Watch it generate a list of conditions, written in Lisp programming language. Your condition file will look something like this:
(
; Identity recode: All groups included as is.
(1)
(2)
(3)
)
This means: "Didn't do anything to any of the groups. Just use them all (elements (1), (2) and (3) of each token) as they are, with the stuff in column (1) as the dependent variable (because it appears first).
Create cell and result files
- In the Cell menu select Load cells to memory.
- Click "OK" when it asks whether to use the tokens and condition files that you see on the screen.
This won't work if there is anything wrong with your token file or conditions file.
A cell file is created, which you can ignore.
A Results file is also created. - You will be asked to select the application values. This means, "how will the dependent variable be examined?" The possible variants of the dependent variable are listed. You can rearrange their order and/or erase some of them. Assume the window shows you the string "YN?".
- If you select "Y" it will do a binary comparison, comparing tokens coded as "Y" for the dependent variable to all tokens with any other variant.
- If you select "YN" it will do a binary comparison, comparing tokens coded with "Y" for the dependent variable to tokens coded with "N", and ignoring any tokens with other variants (e.g., those coded with "?").
- If you select 3 or more characters, all tokens with those codes for the dependent variable will be examined, and the others ignored.
- For a first run-through, select the whole string, but put them in an order with the more relevant ones first. (i.e., put "X" at the end as you won't get much information from it.
Save the Results file under an appropriate name (LIN351_Last-Name_First-Name_1.Res).
The Results file
This file shows you the distribution of the dependent variable with respect to each variant of the independent variables. It looks like this:
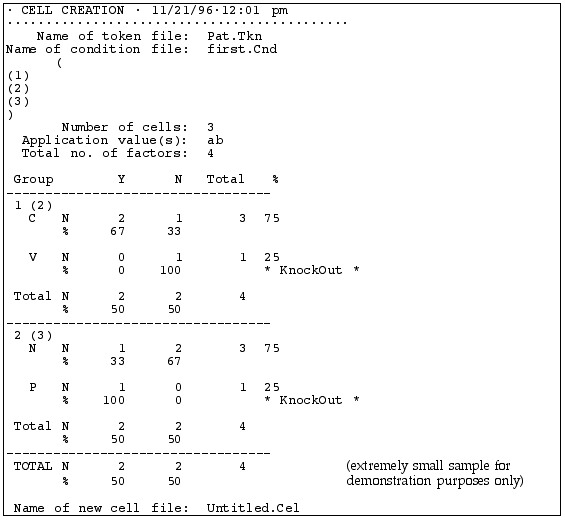 |
When you created it |
| . tkn and .cnd files uses | |
| Conditions you selected | |
| Summary of the distribution | |
| Details of the distribution of variants of the dependent variable (listed across the top) for each independent variable (listed along the left side) |
This table lists the possible variants of the independent variable (Y and N) across the top of the table and the possible variants of each dependent variable, one per row. So this Results file compares tokens with "Y" vs. "N" as the independent variable, i.e., deleted vs. non-deleted (t,d). Note: You will not use “Y” and “N” for your dependent variable.
The first independent variable examined is following segment, with "C" for following consonant and "V" for following vowel. It shows that 67% of the words with a following consonant had deleted (t,d), but 0% of the words with a following vowel had deleted (t,d).
The second independent variable examined is Speaker, with "P" for Pat and "N" for Naomi (pseudonyms, of course). We see that Speaker N deleted (t,d) in 33% of her tokens and Speaker P in 100%
The word * KnockOut * appears in every line that has a "0" value in it.
Finally, we see that overall, for the whole token set, (t,d) deletion occurred 50% of the time, or in 2 out of 4 tokens.
Note: You can copy and paste this table into a Word document, such as a research paper. The columns will line up if you choose the Courier font. It will have strings of spaces rather than tabs, which can be a pain to edit, but you can fix it up as necessary. You can also edit it right in the Results window, which can be dangerous. But, if you do mess it up, you can also reconstruct a new results file by going back to the Cell menu and selecting Load cells to memory.
[Return to top] [Return to syllabus]
Part 8: Report the overall distribution of the dependent variable in the data
- Provide an overall distribution of the dependent variable in the data, as per the following template. Format and label it as in this example:
- Create a second table, similar to Table 1, but that provides a distributional analysis for the social variables.
| Linguistic variables | % [r-1] | N [r-1] | Total # of tokens in the category |
|---|---|---|---|
Preceding vowel |
|||
|
30 |
3 |
10 |
|
40 |
4 |
10 |
|
50 |
10 |
20 |
|
|||
Following context |
|||
|
40 |
4 |
10 |
|
50 |
1 |
2 |
|
|||
TOTAL |
45 |
135 |
300 |
Note: the numbers in these table templates are made up! You will have to replace them with your own numbers and your own categories, depending on what you find in your data.
Submit Tables 1 and 2 as well as a print-out of your Goldvarb .Res file (for Part 8). Use the same type of naming convention as for the previous assignment.
Note: If you don't have a printer and GoldVarb on the same computer, you may need to COPY the contents of your Results file to a Word .doc or some such, save it, and take/send it to a computer with a printer. (Because you won't be able to easily open a .Res file on a computer where Goldvarb isn't installed.)
So, far, you have been doing univariate analysis – looking at only one independent variable at a time. In the next Part, you will learn to how to conduct an analysis with more than one independent variable included. This is very important when your data set does not have a balanced distribution of every combination of every independent variable. That is, when you are dealing with real world data.
[Return to top] [Return to syllabus]
Part 9: Factor Weights
Preparing for multivariate analysis
For this part of the project, you want to conduct an analysis that examines the tokens from all speakers together. You need to use a token file that has the tokens for all six speakers in it.
Use [r-1] as the application value. Be sure to properly label what is being counted, in your tables.
In order to find out which variables are significant, you must create a results file with no "Knockouts, " i.e., no "0" values. This may mean combining or deleting certain factors or factor groups. This process is done by creating a new Conditions file.
Make sure you have principled reasons for the changes you make. This means that it's ok to combine, for example, following stop and following fricative if there was 95% deletion for stops and 100% for fricatives, because (a) stops and fricative are somewhat similar phonetically and (b) the numbers were fairly similar.
Select Recode setup from the Tokens menu. First, copy over the dependent variable from the left to the right side, using the Copy button. Then, for any factor groups that you wish to leave intact, select them on the left side (clicking on their factor group number) and then click Copy.
To exclude a certain factor, click on it on the left side, then click Exclude and say ok. Then copy the factor group. Although the excluded token will still show up, tokens containing it will be ignored in the analysis.
To recode a factor group (normally to combine two categories that were coded separately), select it, choose recode, and then type over the letters on the right to show how you want to recode them.
Make sure it worked. Do this by going back to the Create cells step and creating the distribution tables again and making sure that there are no knock-outs. If it didn't work, try a new condition file. This may get tedious, so you might copy down your coding from the Conditions window. You should be able to figure out most of the Lisp code.
See more information in the "How to recode" document in Bb (or download here; you'll need the sample .tkn file, too).
Multivariate analysis
After producing the usual (distributional) results by selecting Load cells to Memory, choose Binomial, one-level from the Cells menu.
This will create a table showing the Factor Weight of each factor, in addition to the percentages (App/Total). It looks pretty much like all the tables of weights and probabilities you've seen in various articles, but to get the number of tokens, you need to scroll back up to your distributional results. The weights are the values for p1, p2, etc., in the logistic equations we looked at, representing the effect that each factor has on whether the rule applies. (The factor weights are for the "Application value," which is whichever value of the dependent variable prints in the first column of the distribution table that you will have just made.)
It will also show the frequency (percentage) for each factor, for that same Application value. (We will ignore than Input&Weight column.)This report also gives an Input value, which is the overall probability (po) of the application value occurring. That should always be reported.
So for any one combination of factors (e.g., following consonant, Pat as speaker) we could calculate the probability of deletion by combining the po value with the appropriate p1, p2, for each factor group.) But, we don't have to do it because Goldvarb does it for us-- those weights combined will equal the probability of a certain type of token undergoing the rule application.
If you want to look at the constraints conditioning variation for only a subset of your tokens, for example, only tokens from younger speakers, you can use the Recode set-up to exclude tokens from the older speakers. Experiment with this.
Choose Binomial, up & down for analysis of which factors are significant. (You don't need to do this step for the assignment. It's more relevant when you have more factors.)
This analysis takes longer than the one-level, if you have a big token file.
It spits out a lot of text and numbers, but indicates which factors are significant.
You will notice that, generally, the factor groups it finds to be significant are those that have the biggest spread in values in the one-level analysis. If there is a lot of overlap between two different factor groups (i.e., all tokens with a following vowel having been produced by Pat), there may be differences.
Cross-tabulation
If you want to look for that type of overlap, or any interaction between 2 independent variables, choose Cross-tab from the Cells menu and select the 2 groups you are interested in. A new table will be created which shows you their distribution. You can save it as Text or Picture. The "Picture" one looks nicer when copied into another document, but can't be edited, and takes up more disk space. The "Text" one can be edited, and has to be, in order to be legible. Use Courier font to make the columns line up.
For Part 9, submit a document containing the Results file for a one-level binomial analysis for all speakers combined, as Table 3. Be sure to label all columns and rows clearly. It should be arranged like Factor Weight tables we've seen in a number of articles this semester.
See the note above about printing issues.
[Return to top] [Return to syllabus]
Part 10: Comparative analysis
Submit a brief report (1-2 pages of prose) answering the following questions. Include the necessary tables from your own analysis, clearly labeled.
Compare your results with the results presented in Nagy & Irwin (2010). What’s the same? What’s different?
As you do this, think about things like:
How might the age of the speakers be relevant, and how do they compare with their age-mates in the published studies?
Which variant is favoured in by each age group?
How does the proportion of [r-1] in each linguistic context compare to the published results? If it’s different, what could explain the differences?
NOTE: The various files shown as examples are nonsense, un-related, and/or not created from real data.
[Return to top] [Return to syllabus]
Updated March 26, 2012