Heritage Language Variation and Change in Toronto
Objectives | Targeted Languages | References | Personnel | Presentations & Papers | Variables examined
Software | Equipment | Calendar | Instruments | Misc
Description of the Research Project
Given that over half of the world’s population is multilingual from childhood (Tucker 1999), it’s strange that in the field of variationist sociolinguistics, the trend is decidedly to examine one language at a time, essentially treating speakers as monolingual (Nagy & Meyerhoff 2008a). This contrasts with formal linguists’ efforts to detail a Universal Grammar of rules/constraints/parameters that are cross-linguistically relevant. Even in Toronto, touted as the “most multilingual city in the world” (Berkowitz 2003, Toronto Public Library 2006), two major data collection projects within the variationist framework, focus exclusively on English (Tagliamonte 2007, Walker & Hoffman 2008). This Heritage Language Variation and Change (HLVC) Project complements the English projects by examining variation and change in (several of) the heritage languages spoken in the same communities. With the addition of a corpus of naturally-occuring speech in these lesser-studied languages, analysis of the full repertoire of bilingual speakers will be possible. To fully understand how language is used to construct identity, and its variation in a multilingual metropolis, it is essential to examine speakers’ full repertoires, and not treat them as monolingual entities.
Although numerous publications have described heritage language variation in Canada (cf. Budzhak-Jones 1994, Danesi 1985, Fortier 1991, Guardado 2002, Renaud et al. 2001, Vizmuller-Zocco 1993), little progress toward generalizing about how languages vary and evolve can be made due to disparate methodologies. While a general hierarchy of borrowability, (vocabulary> pronunciation > grammar) exists, cross-linguistically valid finer levels of discrimination have not been firmly established, though Matras & Sakel (2007) address this. A major contribution of this project will be a standardized method for quantitative linguistic analysis of variation within multilingual communities, allowing the field to expand beyond its monolingual core. This cohesive program combines elements of code-switching theory which looks at when each language is used, but not at which forms of the language are selected (Poplack 1980, Sankoff & Poplack 1981, Myers-Scotton 1993a,b) with the variationist approach, which quantifies the effects of various contextual forces on the selection of possible forms within one language (Tagliamonte 2006). This further testing of the Labovian or variationist paradigm with languages other than English will also help move beyond our field’s large-language bias (Nagy & Meyerhoff 2008b).
Development of the Heritage Language Documentation (HerLD) Corpus will complement earlier work, allowing analyses which look at cross-generational change in the forms of the languages used as well as trends in selection between available languages. Building on existing methods of determining whether different varieties share the same grammar (Tagliamonte 2006), we will develop a quantification of how similar two grammars are, allowing us to show how much each generation’s variety has shifted from the original (homeland) variety. From this, cross-linguistic comparisons will allow the development of a more generalized understanding of contact-induced language change in a highly multilingual metropolis. Prior to evaluation of the patterns of change over time, adequate description of selected aspects of each language, as currently used in Toronto, must be established. This approach will necessitate ongoing collaboration between formal theory and variationist linguistics, following the principle that “theory can (and should) explain the variable aspects of [language] along with the categorical facts” (Guy 2007, Hume & Nagy 2008).
Objectives
The Heritage Language Variation and Change Project (HLVC) is systematically describing and will compare variable usage and change in several non-official languages spoken in Toronto, a city where 125,905 residents report no knowledge of French or English (City of Toronto 2007). This multilingual and multi-level project will push Labovian variationist research beyonds its monolingually biased core by synthesizing a method examining both intra- and interlanguage choices made by multilingual speakers (who comprise well over half the world’s population).
Specific goals:
- document and describe heritage languages spoken by immigrants and two generations of their descendants in the Greater Toronto Area, contrasting grammars at various degrees of contact to homeland varieties and to English spoken in those communities.
- analyze specific sociolinguistic variables first in isolation and then in contrast. Variables examined so far are listed here.
- develop a standardized framework for examining variation in different languages, which includes a quantification of “similarity,” so that degrees of similarity between grammars can be compared.
- define the types of changes that do and do not occur in “ethnic enclave” languages more fully.
- examine connections between continuous variable (phonetic) approaches, based on speaker production, and discrete variable (phonological) approaches, based on coder perception, in order to develop grammatical descriptions which cohesively describe categorical and variable patterns.
- Encourage speakers of Heritage Languages to participate in research and documentation of the languages. To this end, qualified students are invited to enroll in the following:
- Additionally, we sometimes hire student research assistants (check for postings at The U of T Career Centre). We also train qualified volunteers who are interested in getting experience working on a large-scale research project.
Targeted Languages
-
Korean
-
Russian
-
Faetar
-
Italian
- Ukrainian
- Cantonese
|
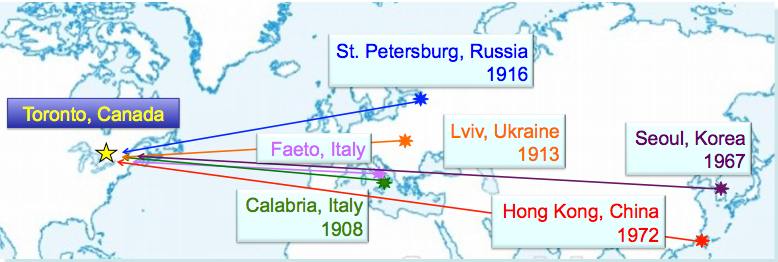
The dates in the map above are based on available information regarding the establishment of the first Toronto-area church offering services in each language; or best estimate of arrival date of first group of immigrants. |
These languages have been strategically selected for available resources, contrasting inherent traits, and differing degrees of divergence from English. Contrasting with Italian, for which there are vigorous long-standing communities in Toronto (but only 16% use of Italian at home by ethnic Italians), Korean represents a recent immigrant population where 66% speak Korean. Russian is of intermediate standing between them, with waves of immigration since the 1980’s and 49% Russian use at home. Faetar enjoys the same longevity as Italian, but is a far smaller community. Fieldwork will be in the neighborhoods with the highest concentration of each language: within Ward 9 for Italian, 10 for Russian and 23 for Korean (all demographic facts from Statistics Canada’s 2006 Census).
In the future, additional languages will be investigated, as student interest allow, to develop a series of studies exploring both newer and older communities and a range of typological diversity. Candidates include Hindi, Portuguese, Polish, for which there are different waves of immigration, allowing us to see more clearly how length of contact influences change, and Chinese, a newer community which is also well represented in the two existing sociolinguistic corpora of Toronto English.
We define our generations as follows:
HLVC Participant Criteria
- 1st generation: born in the homeland (see map) and moved to the Greater Toronto Area after age 18. Here at least 20 years.
- 2nd generation: born in the GTA (or came from homeland before age 6) and parents qualify as 1st generation
- 3rd generation: born in the GTA and parents qualify as 2nd generation
All participants are fluent enough for a one-hour conversation in the Heritage Language
We seek interested collaborators who would like to contribute data, compare our analyses with homeland data, or otherwise contribute. Students who want to get involved, check out the options here.
If you interested in using our data for further analysis, the first step is to contact one of the PIs. To request access to this project's data, please submit a completed HLVC Corpus Use Form to one of the PIs for consideration.
This research is supported by SSHRC Standard Research Grant 410-2009-2330 (2009-2012).
|